『论文阅读』Generating Videos With Scene Dynamics
/ / 点击 / 阅读耗时 4 分钟来源:NIPS2016
这篇论文提出了一个基于GAN的网络模型,同时可以进行视频识别和视频生成的task。
Task
Video recognition & video Generation.
即利用一些Unlabeled videos 去训练模型同时解决识别问题和视频生成的任务。
实验表明:
1. 模型可以生成一些短小的视频并且效果较好
2. 可以根据static image 预测之后的图片序列
3. 模型学习到的特征可以很好的用来进行图片分类
model
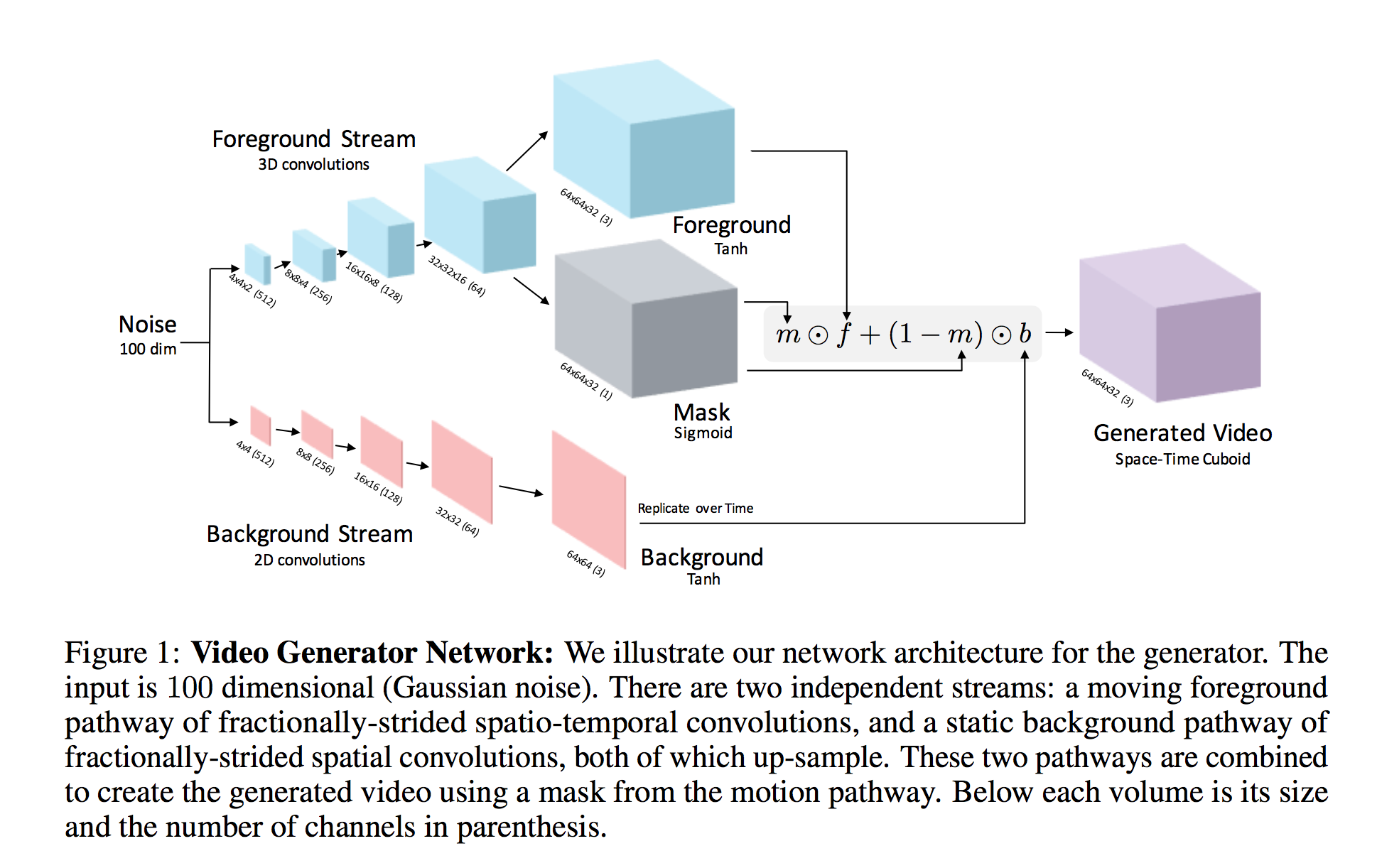
OneStream Architecture:
在Figure 1 中蓝色的部分即为 One Stream Architecture。
Two StreamArchitecture:
即Figure 1 完整版,因为One StreamArchitecture不能很好的建模实际情况:视频通常由静态的背景和动态的前景构成。
所以设计了双路的生成模型分别用来生成静态背景 Background 和前景动态Foreground。然后利用:
\[ G_2(z) = m(z)\odot f(z) + (1-m(z))\odot b(z). \] 合并前景和背景。
DiscriminatorNetwork
直接利用和生成模型对称的卷积网路结构用来作为判别模型。
Learningand Implementation
利用SGD来训练模型。激活函数采用ReLU。
数据集的处理
对于特征表示的学习可以直接利用unlabeled videos.
对于GAN网络的训练,采用Places2 pre-trained model 来进行过滤视频(依据场景类别),最后利用的四个场景类别:golf course, hospital rooms, beaches andtrain station.
同时对于相机抖动进行处理,防止出现背景变化的情况。
实验结果
tinyvideo 可以看到生成的动态视频。

对于实验结果如何评价
Evaluation Metric: We quantitatively evaluate our generation using apsychophysical two-alternative forced choice with workers on Amazon MechanicalTurk.
即人工评判,对照实验为 AutoEncoder (即Discriminator>endoer,Generator->decoder)
Video Representation Learning
即将GAN模型的Discrimination部分作为特征视频表示学习的模型。
实验证明效果挺好。
Future Generation
即CGAN (Conditional GAN), 利用静止的图片作为输入的condition。
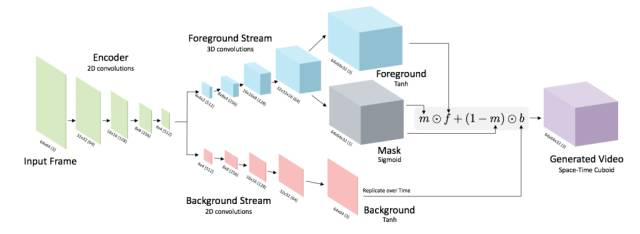
同时加一个约束:input 和 generator生成的第一帧直接的L1 loss.
确保生成的视频和输入保持一致。